Table of Contents
Harnessing Machine Learning for Advanced Text Analysis
by
December 10, 2025

by
December 10, 2025
Machine Learning for Text Analysis is reshaping how organizations process and understand language-based data, turning it into structured insights and actionable data. From customer reviews to business reports, it helps uncover meaning that was once hidden in unstructured text.
The global text analytics market is projected to reach approximately USD 12.75 billion in 2025, up from about USD 10.86 billion in 2024. Additionally, another report forecasts that the market will reach USD 35.5 Billion by 2033, with a compound annual growth rate (CAGR) of 15% in the text-analytics sector. By following clear workflows—preparing data, training models, evaluating results, and deploying solutions—businesses can adopt machine-learning-driven text analysis with confidence and maintain reliable performance as language and data evolve.
In this guide, we will cover how machine learning on text analysis works, its key applications, pros and cons, and a clear step-by-step guide to applying it for smarter business insights.
Build Smarter Text Analysis Systems
Turn raw text into real business insights with our custom-built machine learning models designed to process language with precision.
What is Machine Learning for Text Analysis
Machine Learning for text analysis involves using algorithms that can automatically understand, process, and derive insights from textual data. These systems identify linguistic structures, detect patterns, and interpret context to support decision-making and automate language-based tasks. Text analysis powered by machine learning enables organizations to handle vast text datasets efficiently, turning unstructured language into structured, actionable knowledge.
How It Works
Machine learning for text analysis operates through a structured process that ensures data-driven accuracy and scalability. Each phase contributes to building models that adapt and improve over time, offering consistent performance across varied datasets.
1. Data Preparation
Data preparation is the foundation of text analysis. It involves collecting, cleaning, and formatting raw text so it can be processed effectively by machine learning algorithms. The goal is to ensure data consistency and accuracy before model training begins. A well-prepared dataset reduces errors and improves model reliability.
2. Model Training
During model training, the system learns to recognize linguistic patterns using labeled or unlabeled data. The model adjusts its parameters by identifying correlations and relationships between text features and desired outcomes. Proper training requires the right algorithm, balanced data, and defined evaluation metrics to avoid overfitting or underfitting.
3. Model Evaluation
Once trained, the model undergoes testing to assess its ability to accurately interpret unseen data. Metrics like precision, recall, and F1-score provide insight into its performance. Continuous evaluation ensures that the system remains relevant as language patterns shift, leading to better real-world performance over time.
4. Deployment
Deployment marks the transition from experimentation to practical use. The trained model is integrated into applications that analyze live or incoming text data. Proper deployment includes monitoring, scalability adjustments, and updates to maintain consistent performance as the system encounters new linguistic data.
Related read: Top Foundations and Trends in Machine Learning.
Types of Machine Learning for Text Analysis
Different learning methods power text analysis, each suited for specific objectives and data structures. The two main categories are supervised and unsupervised learning. Together, they enable a range of applications from classification to topic discovery.
1. Supervised Learning
Supervised learning uses labeled datasets where each example has an assigned outcome. The algorithm learns from this input-output mapping to make predictions on new text data. It’s particularly effective for sentiment analysis, spam detection, or intent recognition. As more labeled examples are added, the model’s precision and contextual understanding continue to improve.
2. Unsupervised Learning
Unsupervised learning deals with unlabeled data and aims to identify natural groupings or hidden structures within text. Machine learning techniques like clustering and topic modeling uncover relationships between words and documents. This approach helps summarize large datasets, discover emerging themes, and detect anomalies without relying on prior labeling or human intervention.
Pros of Machine Learning for Text Analysis
Machine learning delivers several advantages that make text analysis efficient and insightful. Automation, pattern recognition, adaptability, and accuracy are among its strongest benefits.
1. Automation and Efficiency
Machine learning automates time-consuming text processing tasks that once required manual review. It enables systems to classify messages, extract entities, and detect tone with speed and precision. By streamlining analysis, teams can handle larger volumes of text data, reduce operational costs, and focus on higher-value strategic work.
2. Pattern Discovery
Through advanced pattern recognition, machine learning identifies trends and correlations within massive text datasets. It can detect subtle shifts in customer sentiment, uncover recurring issues in feedback, and highlight emerging topics. This ability to discover underlying relationships turns unstructured text into actionable insights for research, business intelligence, and policy-making.
3. Adaptability
Machine learning models continuously learn from new inputs, refining their understanding as language and user behavior evolve. They adjust to new words, contexts, or formats without extensive manual reprogramming. This adaptability ensures sustained accuracy across industries that handle rapidly changing data streams, from social media monitoring to market sentiment analysis.
4. High Accuracy
When trained on high-quality data, machine learning models achieve impressive precision in identifying sentiment, classifying topics, or summarizing content. Their ability to process linguistic nuances helps eliminate human inconsistency. This level of accuracy not only boosts trust in automated analysis but also enhances the overall reliability of data-driven decisions.
Cons of Machine Learning for Text Analysis
Despite its advantages, machine learning introduces certain challenges. These machine learning challenges include dependence on data quality, computational demand, algorithmic bias, and difficulties in explaining model reasoning.
1. Data Dependency
Machine learning models depend heavily on the volume and quality of their training data. Incomplete or biased datasets can distort results and weaken predictions. Ensuring balanced, diverse, and well-curated data is essential to prevent skewed interpretations and maintain fairness across automated text analysis systems.
2. Resource-Intensive
Training sophisticated models requires substantial computing power, storage, and processing time. Large-scale neural networks demand high-performance hardware and continuous optimization. This makes implementation costly, particularly for smaller organizations with limited infrastructure or technical capacity to support full-scale machine learning pipelines.
3. Bias Risk
Bias in machine learning arises when training data reflects human or systemic prejudices. These biases can lead to unfair classifications or misleading insights. Continuous data auditing, algorithmic transparency, and bias mitigation practices are necessary to ensure balanced, responsible, and trustworthy model performance.
4. Lack of Interpretability
Complex models, especially deep learning architectures, can be challenging to interpret, even for experienced machine learning development companies. Their internal logic may not clearly explain how predictions are formed, limiting transparency. This “black box” effect makes it challenging to validate decisions, particularly in fields where accountability and regulatory compliance are critical.
Common Applications of Machine Learning for Text Analysis
Machine learning enables a wide array of text-based applications that transform unstructured content into measurable insights. These applications serve industries ranging from finance and marketing to healthcare and cybersecurity. Here they are:
1. Sentiment Analysis
Sentiment analysis uses machine learning to determine emotional tone within text, distinguishing between positive, negative, and neutral sentiments. It helps businesses understand customer satisfaction, track brand perception, and improve engagement strategies. This technique is commonly applied in product reviews, social media monitoring, and customer service analysis to support more informed decision-making.
2. Topic Modelling
Topic modeling groups similar texts and identifies recurring themes using methods like Latent Dirichlet Allocation (LDA) or Non-negative Matrix Factorization (NMF). It’s especially valuable for exploring large document collections, research papers, and user-generated content. By revealing patterns and subject clusters, organizations can summarize complex information and prioritize relevant insights without extensive manual reading.
3. Text Classification
Text classification assigns predefined categories to textual content based on learned linguistic features. It’s frequently used for spam filtering, content moderation, intent detection, and document organization. By training models on labeled examples, text classification systems streamline sorting tasks, enhance search relevance, and deliver faster and more accurate information management across digital machine learning platforms.
4. Named Entity Recognition (NER)
Named Entity Recognition identifies and labels key entities in text, such as people, organizations, dates, and locations. It enables systems to extract structured information from unstructured data, making it useful across fields such as journalism, law, and finance. NER enhances knowledge graphs, improves document indexing, and strengthens information retrieval across large datasets.
5. Text Summarization
Text summarization condenses long passages into concise, meaningful summaries while preserving essential details. Machine learning models, including extractive and abstractive approaches, are applied to news aggregation, academic research, and corporate reporting. This process improves information accessibility, saves time, and ensures users can quickly grasp key points without having to read full documents.
Step-by-Step Guide to Apply Machine Learning for Text Analysis
Applying machine learning to text analysis involves a structured workflow that moves from defining objectives to maintaining deployed models. Following these stages ensures accuracy, consistency, and sustainable performance.
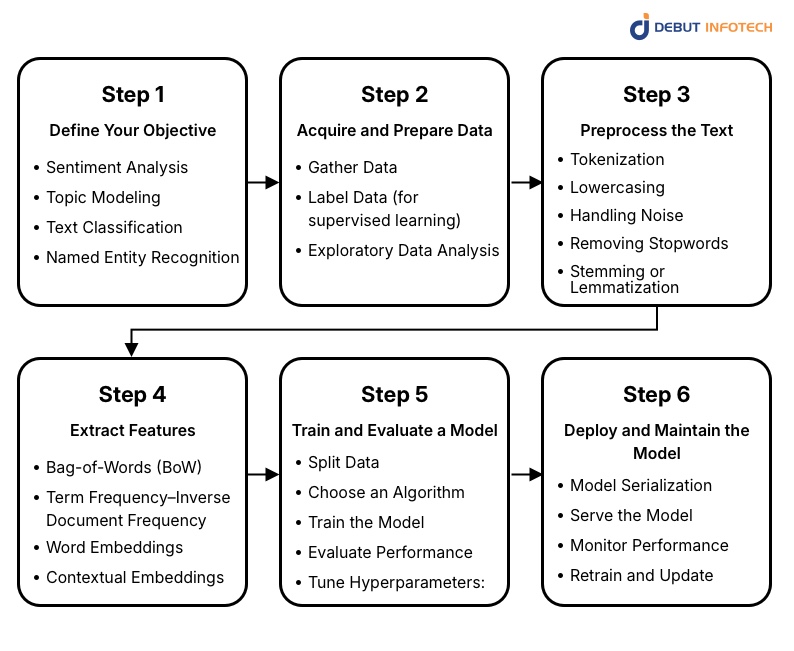
Step 1: Define Your Objective
Every project begins with a clear goal. The objective determines which machine learning algorithms for text analysis, datasets, and evaluation methods to use. Whether it’s detecting sentiment, identifying topics, classifying documents, or recognizing named entities, a well-defined aim streamlines the modeling process.
Examples of objectives:
a) Sentiment Analysis: Identify emotional tone in reviews or feedback to assess public opinion, customer satisfaction, and brand perception through automated text interpretation.
b) Topic Modeling: Discover recurring themes and topics across large text datasets, enabling efficient document summarization, trend analysis, and content categorization.
c) Text Classification: Automatically categorize documents, emails, or messages into structured labels to simplify organization and streamline automated decision-making workflows.
d) Named Entity Recognition (NER): Detect and extract key information such as names, places, or organizations from unstructured text for structured data generation.
Step 2: Acquire and Prepare Data
Data acquisition and preparation form the backbone of successful machine learning model development. Clean, representative data helps prevent bias and improves accuracy across tasks.
Data preparation steps:
a) Gather Data: Collect raw text from sources like news articles, reviews, customer feedback, or web content, depending on the problem’s scope and industry focus.
b) Label Data (for supervised learning): Assign meaningful tags or categories to each text sample manually or semi-automatically to guide supervised learning algorithms during training.
c) Exploratory Data Analysis (EDA): Examine data distribution, detect outliers, identify frequent words, and visualize trends to better understand content characteristics before preprocessing.
Step 3: Preprocess the Text
Preprocessing transforms raw text into a consistent format suitable for machine learning text analysis. This stage enhances signal clarity and model interpretability.
Common preprocessing techniques:
a) Tokenization: Split text into smaller components, such as words or sentences, to facilitate detailed linguistic analysis and feature extraction.
b) Lowercasing: Convert all text to lowercase to maintain uniformity and prevent misclassification caused by capitalization differences in datasets.
c) Handling Noise: Remove irrelevant characters, punctuation, special symbols, or corrupted data elements to enhance text clarity and quality.
d) Removing Stopwords: Eliminate common words like “the” or “and” that carry limited semantic meaning to reduce dimensionality and focus on important terms.
e) Stemming or Lemmatization: Reduce words to their root or base form, helping models recognize variations of the same term during training and prediction.
Read also other blog – AI vs Machine Learning: What’s the Difference and Why It Matters?
Step 4: Extract Features
Feature extraction converts text into numerical representations that machine learning models can interpret. Selecting the right method impacts model efficiency and performance.
Popular feature extraction methods:
a) Bag-of-Words (BoW): Represent text by counting word occurrences, capturing frequency-based information for traditional machine learning models.
b) Term Frequency–Inverse Document Frequency (TF-IDF): Measure word importance relative to document context, improving feature relevance in classification and clustering tasks.
c) Word Embeddings (Word2Vec, GloVe): Encode semantic relationships between words using dense vector representations, enhancing contextual understanding.
d) Contextual Embeddings (BERT): Capture dynamic word meanings based on context within sentences, allowing deeper comprehension of linguistic structures.
Step 5: Train and Evaluate a Model
Training and evaluation shape how effectively the system interprets language. Data is split into training and testing sets to validate performance. AI Algorithms are chosen based on the task: logistic regression for classification or transformers for advanced understanding. Evaluation metrics help gauge accuracy, while hyperparameter tuning optimizes model strength.
Process for training and evaluation:
a) Split Data: Divide data into training, validation, and testing subsets to ensure models generalize well on unseen samples.
b) Choose an Algorithm: Select a machine learning or deep learning algorithm aligned with project requirements and computational resources.
c) Train the Model: Feed the prepared data into the algorithm to learn word patterns, relationships, and category distinctions.
d) Evaluate Performance: Measure precision, recall, F1-score, and accuracy to assess how effectively the model performs across test data.
e) Tune Hyperparameters: Adjust learning rate, batch size, or model depth to improve stability and predictive performance.
Step 6: Deploy and Maintain the Model
Once validated, the model moves into production. Deployment involves serialization, serving predictions through APIs, and monitoring for drift or degradation. Regular retraining ensures continued alignment with changing text inputs and maintains consistent analytical accuracy.
Steps for deployment and maintenance:
a) Model Serialization: Convert the trained model into a deployable format like Pickle or ONNX for integration into applications.
b) Serve the Model: Deploy the serialized model through APIs or web services to handle live prediction requests.
c) Monitor Performance: Track model accuracy, latency, and data drift to detect declining performance in real-world environments.
d) Retrain and Update: Periodically retrain using fresh data to maintain accuracy and adapt to evolving language trends.
Partner with Experts in Text Intelligence
Collaborate with our machine learning specialists to build reliable, high-performance text analysis solutions that transform your business data into insight.
Conclusion
Machine Learning for Text Analysis has become essential for turning unstructured language into actionable insight. By combining natural language processing (NLP), robust models, and continuous evaluation, organizations can detect sentiment, extract entities, summarize content, and prioritize issues at scale.
Proper data practices and ongoing monitoring reduce bias and maintain accuracy, while thoughtful deployment preserves transparency and usefulness.
Investing in these capabilities delivers faster decision-making, clearer customer understanding, and sustained operational value across industries. It supports scalable analytics, compliance, and measurable ROI when governed.
FAQs
Q. What is the machine learning model for text analysis?
A. A machine learning model for text analysis helps computers understand and interpret human language. It learns from large text datasets to identify patterns, classify sentiments, extract topics, or summarize content. Common models include Naive Bayes, SVMs, Decision Trees, and modern neural networks like BERT.
Q. How to use machine learning for text classification?
A. To use machine learning for text classification, start by gathering and cleaning text data. Convert the text into numerical features using techniques like TF-IDF or word embeddings. Then train an algorithm—such as Logistic Regression or an SVM—on labeled data to automatically categorize new, unseen text.
Q. Which ML algorithm is best for text classification?
A. There’s no single best algorithm for all text classification tasks. For smaller datasets, Naive Bayes or Logistic Regression works well. For large or complex language data, deep learning models like LSTM or transformer-based architectures such as BERT often deliver higher accuracy and better context understanding.
Q. What is the LLM model for text analysis?
A. An LLM, or Large Language Model, is an advanced machine learning system trained on massive text datasets to understand and generate human-like text. Models like GPT and BERT are used for tasks such as summarization, sentiment analysis, question answering, and text generation, offering high contextual awareness and accuracy.
Q. What are the 5 steps of NLP?
A. The five main steps of Natural Language Processing (NLP) are: text preprocessing, tokenization, feature extraction, model training, and evaluation. These steps help machines clean, structure, and interpret human language so they can perform tasks such as classification, translation, and sentiment detection effectively.
Our Latest Insights



Leave a Comment