Table of Contents
Home / Blog / Tokenization
NLP Tokenization Guide: Methods, Types, Tools & Use Cases Explained
by
May 29, 2025
by
May 29, 2025
NLP Tokenization is a foundational step in natural language processing that involves breaking text into smaller, manageable units called tokens. These tokens—whether words, characters, or subwords—enable machines to interpret human language more effectively. From text classification and sentiment analysis to powering chatbots and voice assistants, tokenization plays a critical role across countless applications.
The rapid growth of the NLP market highlights the significance of tokenization. According to Fortune Business Insights, the global NLP market size was valued at USD 24.10 billion in 2023 and is projected to reach USD 158.04 billion by 2032, exhibiting a CAGR of 23.2% during the forecast period.
Moreover, tokenization is a critical component in numerous NLP tasks. A study highlighted by MoldStud indicates that over 70% of businesses leveraging tokenization techniques report improved accuracy in sentiment classification.
This guide explores how NLP Tokenization works, why it matters, its core challenges, the various types and methods, and the top tools and libraries professionals use today.
See How Our Tokenizers Handle Complex Text
From multilingual input to industry jargon, our tokenization solutions are designed to adapt. Let us show you how flexible NLP tokenization should work.
What is Tokenization in NLP?
Have you ever wondered: what does tokenization mean in NLP?
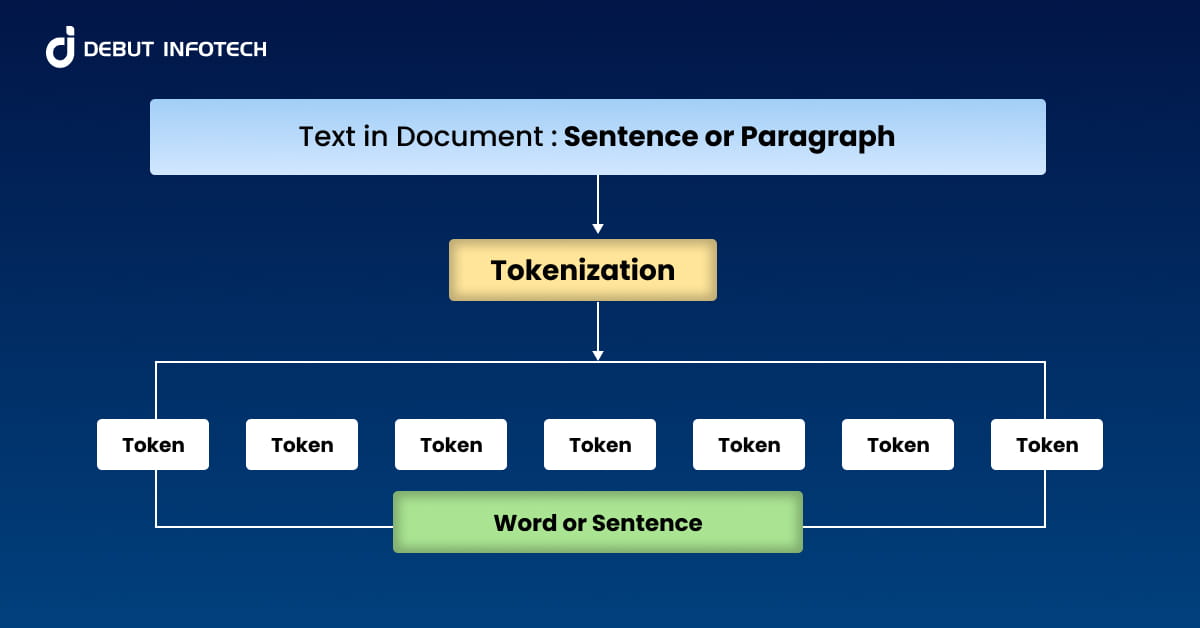
Tokenization in Natural Language Processing (NLP) refers to the process of breaking down text into smaller, manageable units known as tokens. Depending on the method applied, these tokens can be words, characters, subwords, or sentences.
Tokenization is foundational in preparing textual data for computational analysis and machine learning model training. It enables algorithms to systematically analyze language by transforming free-form text into structured elements, facilitating accurate parsing, categorization, and interpretation.
How Does Tokenization Work in NLP?
Tokenization unfolds through a series of deliberate steps, each designed to progressively refine raw input into useful data points for NLP tasks:
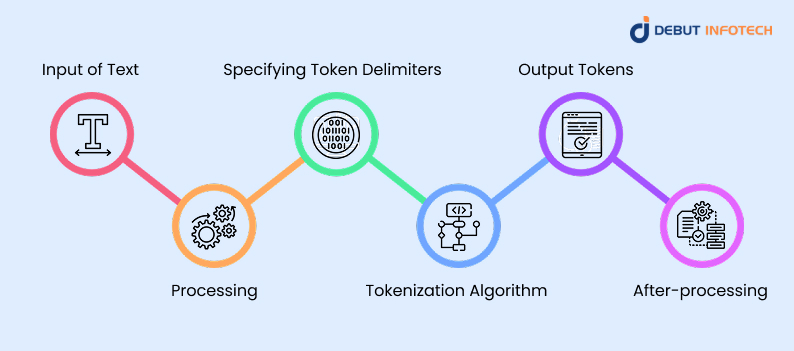
1. Input of Text
The tokenization process starts with raw textual input, which could come from various sources like user queries, documents, emails, or speech transcripts. This raw data may include irregular punctuation, inconsistent casing, or noise, all of which must be prepared for tokenization to ensure meaningful downstream analysis.
2. Processing
Before splitting into tokens, the text is normalized to reduce variability. This may include lowercasing, removing stopwords, correcting misspellings, or eliminating special characters. These adjustments improve consistency, allowing the tokenization algorithm to identify true linguistic units and improving the accuracy of further natural language processing tasks.
3. Specifying Token Delimiters
Delimiters—like whitespace, punctuation, or symbols—guide where tokens begin and end. Depending on the language or application, these boundaries may vary. Some tokenizers use custom rules or pre-learned models to determine delimiters that best preserve the structure and meaning of the original input text.
4. Tokenization Algorithm
An algorithm, such as rule-based or statistical tokenization, processes the text using the chosen delimiters or learned patterns. It converts input into distinct tokens, handling language-specific nuances, abbreviations, or ambiguous cases. The precision of this algorithm significantly affects downstream NLP outcomes like classification, translation, or parsing.
5. Output Tokens
After processing, the tokenizer returns a structured list or sequence of tokens. These are the fundamental elements that models will analyze. Each token carries syntactic or semantic value and becomes an atomic unit for further processes like tagging, embedding, sentiment analysis, or model input representation.
6. After-processing
Post-tokenization steps like stemming, lemmatization, or token filtering may be applied. These refine token quality by reducing redundancy, standardizing word forms, or removing uninformative items. This stage optimizes tokens for modeling, ensuring they capture useful linguistic patterns without unnecessary noise or duplication.
The True Reasons Behind Tokenization in NLP
Tokenization is what allows machines to truly understand language. By segmenting text into units with computational value, tokenization transforms linguistic complexity into something structured and accessible. It’s the bridge between chaotic real-world language and the ordered patterns that machines can learn from.
Whether training a sentiment classifier or a generative AI model, tokenization provides the groundwork for every subsequent operation. For machine learning development companies, mastering this step is essential to building high-performing, ethical, and multilingual NLP systems.
As NLP tools become more nuanced and multilingual, this initial step is more important than ever for accuracy, performance, and ethical design.
Why is Tokenization Important in NLP?
Tokenization is essential because it enables a wide range of core NLP tasks:
1. Text Classification
NLP Tokenization transforms raw text into analyzable segments, enabling models to detect patterns, keyword frequencies, and contextual signals. This is critical in classifying documents or messages into categories—such as spam, news topics, or legal tags—by making text digestible and machine-readable for statistical or deep learning classifiers.
2. Sentiment Analysis
By breaking text into discrete tokens, sentiment analysis algorithms can identify emotional cues like adjectives or emotive expressions. Tokens help models detect sentiment orientation—positive, negative, or neutral—at sentence or document level, improving accuracy in applications like customer feedback interpretation or social media monitoring.
3. Named Entity Recognition (NER)
Tokenization is essential for identifying names of people, places, organizations, or time expressions. Proper segmentation ensures that entity boundaries are correctly marked, preventing overlap or omission. This accuracy is vital for applications in search, compliance, and knowledge graph construction where entity-level precision is required.
4. Machine Translation
In translation systems, tokenization ensures that each linguistic unit is clearly defined before being mapped to a corresponding expression in the target language. Fine-grained tokenization captures word roots, idiomatic phrases, and morphological structures, which are essential for producing grammatically correct and contextually appropriate translations.
Use Cases of NLP Tokenization
Tokenization quietly powers many of the NLP-driven tools we rely on daily:
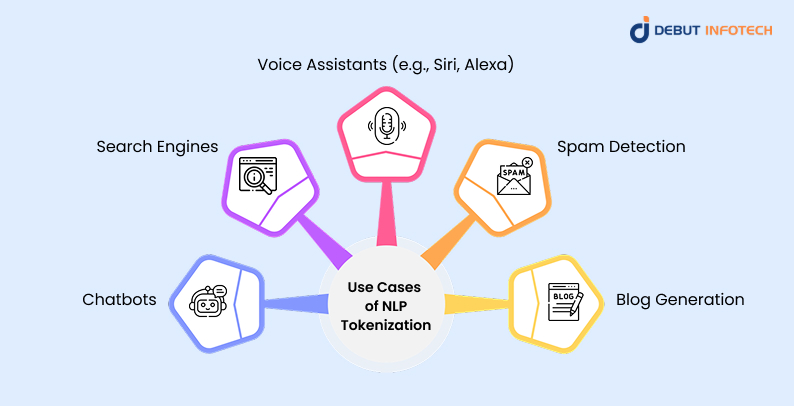
1. Chatbots
Tokenization enables chatbots to interpret user messages more effectively by breaking text into manageable parts. This allows intent recognition engines to process queries, match them with predefined responses, or trigger workflows. It also helps identify key phrases or commands, enabling bots to respond accurately, even in conversational or informal language formats.
2. Search Engines
NLP Tokenization helps search engines parse and index user queries as well as documents. By identifying individual tokens, search algorithms can match queries to relevant pages more accurately. It supports autocomplete, spell-check, and synonym handling while enabling semantic search, which improves result relevance and user satisfaction across large-scale databases and websites.
3. Voice Assistants (e.g., Siri, Alexa)
Voice assistants rely heavily on tokenization after converting speech to text. Tokenized input allows NLP models to detect commands, locations, or scheduling information. This precision helps assistants accurately perform actions like setting reminders or fetching data, even when the speech contains pauses, informal phrases, or unclear boundaries between spoken words.
4. Spam Detection
Tokenization aids in identifying common spam patterns by isolating suspicious keywords, repeated phrases, or non-standard characters. It supports feature extraction for classifiers that detect spam emails or messages. By consistently parsing content, tokenization allows detection systems to work across languages and formats, improving spam filters’ effectiveness and adaptability.
5. Blog Generation
In automated or assisted blog writing, NLP tokenization helps generate coherent content by identifying input structure and guiding model output. Tools like GPT rely on token sequences to continue writing logically. It ensures that sentence flow, grammar, and topical relevance are maintained throughout long-form content, enhancing readability and human-like composition.
Tokenization Challenges in NLP
Despite its value, tokenization presents several challenges for NLP in business that demand careful engineering:
1. Lack of Clear Word Boundaries
Some languages, like Chinese or Thai, do not use spaces to separate words, making tokenization complex. Determining accurate word boundaries requires advanced models or dictionaries. Without clear segmentation, errors in token mapping can significantly affect NLP tasks like translation, summarization, or information retrieval.
2. Handling Contractions and Compound Words
Languages like English contain contractions (e.g., “don’t”) and compound terms (e.g., “mother-in-law”) that pose tokenization issues. Improper splitting can alter semantic meaning. Tokenizers must recognize these patterns and either preserve them or split them correctly based on the context and the needs of the downstream NLP task.
3. Symbols and Special Characters with Contextual Meaning
Special symbols such as hashtags (#), mentions (@), or emojis often carry meaning in social media or informal text. Depending on context, they may represent metadata or emotional cues. Tokenizers must decide whether to isolate, retain, or discard these elements, which directly affects sentiment and topic modeling accuracy.
4. Multi-language Tokenization in Natural Language Processing
Tokenizing multi-lingual content, such as a tweet written in Hinglish (Hindi-English mix), is challenging. Each language may have different grammar rules and token structures. Effective tokenization requires language detection and switching mechanisms, making multilingual tokenization a complex but necessary function for global NLP applications.
5. Contextual Awareness
Tokenizers cannot often understand the surrounding context, which leads to poor handling of polysemous words, idioms, or ambiguous punctuation. Without contextual modeling, token boundaries may misalign with linguistic meaning, limiting accuracy in high-level NLP tasks like summarization or named entity recognition.
Overcoming these hurdles is key to building robust, globally scalable NLP applications.
Kinds of Tokenization in NLP
Tokenization methods vary depending on the level of analysis required:
1. Character Tokenization
This method splits text into individual characters. It’s useful for languages with complex morphology or for spelling correction tasks. While it offers fine-grained control, it often lacks semantic clarity, as characters don’t inherently carry meaning unless analyzed in sequence or within specific linguistic structures.
2. Word Tokenization
Word tokenization separates text based on spaces and punctuation, treating each word as a token. It’s commonly used in English and other space-delimited languages. However, it can struggle with contractions, punctuation, or multilingual input unless combined with smarter rules or pre-trained models.
3. Subword Tokenization
Subword methods like Byte-Pair Encoding (BPE) or WordPiece break words into smaller meaningful units. These are especially helpful in handling rare or compound words. Subword tokenization helps prevent out-of-vocabulary issues and allows deep learning in predictive analytics models to represent unseen words by combining known subword units effectively.
4. Sentence Tokenization
This technique divides text into complete sentences using punctuation and capitalization cues. It’s vital for document processing, summarization, or translation tasks. However, detecting sentence boundaries accurately can be difficult with abbreviations, dialogue, or informal writing, making intelligent rules or models necessary.
5. N-gram Tokenization
N-gram tokenization creates overlapping word or character groups of size ‘n’ (e.g., bigrams, trigrams). This helps capture phrase-level patterns and co-occurrences, which are valuable in text classification, language modeling, or predictive typing. However, it increases data dimensionality and may require more computation or memory.
Each type serves different modeling goals and handles text complexity at varying levels.
Which Kind of Tokenization Should You Use?
Choosing the right type of tokenization comes down to your use case, language, and computational constraints. If you’re working with English tweets, word tokenization might be enough.
For low-resource languages or complex domains like legal or biomedical text, subword or sentence tokenization may offer better granularity and generalization.
When performance and model size are a concern, subword methods like Byte-Pair Encoding help reduce vocabulary bloat without sacrificing accuracy.
The bottom line? There’s no one-size-fits-all answer—evaluate based on the context you’re modeling and the systems you’re integrating with. But, if you’re stuck, you can reach out to machine learning consulting firms for support.
Tokenization Methods: Popular Approaches in NLP
Several widely adopted techniques define the state-of-the-art in NLP tokenization:
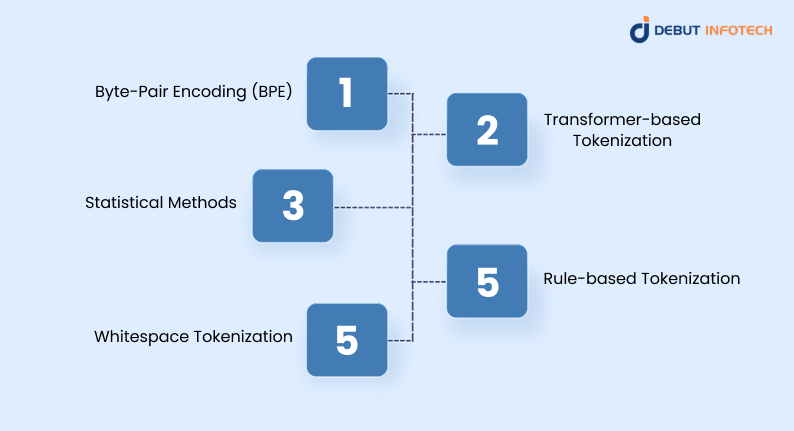
1. Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) iteratively replaces the most frequent pairs of characters or subwords with single tokens. It’s especially effective for compressing vocabulary and handling rare or unknown words. BPE helps NLP models generalize better by representing new terms through known subword units, which enhances language understanding and generation tasks.
2. Transformer-based Tokenization
Transformer tokenization is used in models like BERT and GPT, and it often employs subword methods such as WordPiece or SentencePiece. It enables efficient representation of large vocabularies with fewer tokens. This method balances token granularity and semantic meaning, improving downstream tasks like translation, summarization, and sentiment analysis while supporting multilingual processing in large-scale models.
3. Statistical Methods
Statistical tokenization analyzes large corpora to learn probable token boundaries based on frequency and co-occurrence statistics. It’s useful for languages without clear delimiters and in unsupervised NLP tasks. This method adjusts to real data distributions, offering flexibility. However, it may lack the linguistic precision of rule-based or model-guided approaches in complex contexts.
4. Rule-based Tokenization
Rule-based tokenizers use handcrafted linguistic rules to define how text is split—relying on punctuation, white space, and syntactic patterns. They are easy to understand and implement but may not adapt well to informal, multi-language, or inconsistent input. However, they remain useful in constrained environments or domain-specific applications with predictable input patterns.
5. Whitespace Tokenization
Whitespace tokenization is the simplest approach, dividing text based on spaces. It’s fast and works well for clean, structured English text. However, it doesn’t handle punctuation, contractions, or compound terms effectively. This method is mostly used in basic NLP pipelines or as a preprocessing step before more complex tokenization machine learning techniques.
Tokenization Tools and Libraries
The NLP community benefits from mature, battle-tested tools designed to simplify tokenization:
1. NLTK (Natural Language Toolkit)
NLTK offers a comprehensive suite of tokenizers, including word, sentence, and regexp-based tokenizers. It supports educational use and research, providing detailed control over token rules. Its flexibility makes it suitable for academic NLP tasks. However, it may be slower for production-scale applications compared to more modern tokenization libraries.
2. spaCy
spaCy provides industrial-strength, fast, and accurate tokenization with multilingual support. Its tokenizer is designed to align with modern NLP pipelines, offering integration with part-of-speech tagging, dependency parsing, and entity recognition. spaCy uses pre-trained language models, ensuring tokens are linguistically meaningful, and is often favored in real-time and scalable NLP applications.
3. HuggingFace Tokenizers
HuggingFace’s `tokenizers` library offers highly optimized, fast tokenization built for modern transformer models. It supports BPE, WordPiece, and other subword techniques essential for models like BERT or GPT. It handles large datasets efficiently, supports parallel processing, and allows custom training, making it ideal for advanced deep learning pipelines and fine-tuning tasks.
The Future of Tokenization in NLP
Tokenization is evolving fast. The field is moving beyond static rules toward context-aware systems that can adapt to new languages, dialects, and even multimodal input. Future tokenizers may rely more on self-supervised learning, embedding structure directly from the data rather than relying on pre-defined rules. We’re also likely to see tokenization converge with other preprocessing steps, resulting in cleaner, more efficient NLP pipelines. As AI becomes increasingly conversational and personalized, tokenization will remain central, quietly shaping how machines understand us, one token at a time.
Fix Tokenization Errors Once and for All
Tired of weird splits, missing words, or token mismatches? We audit and rebuild your tokenization process so your models stop guessing and start learning.
Conclusion
As NLP technology evolves, so does the sophistication of NLP tokenization methods. Whether you’re building chatbots, training transformer models, or working on multilingual applications, choosing the right type and tokenization method is crucial. Understanding its challenges and future direction will help developers, researchers, and businesses build more accurate and context-aware language processing systems.
FAQs
Q. What is an example of a tokenizer?
A. An example of a tokenizer is the WordPiece tokenizer used by BERT. It breaks text into subwords, so something like “unhappiness” becomes \[“un”, “happiness”]. This helps models handle rare or unknown words more efficiently.
Q. What is the most common tokenizer?
A. The most common tokenizer today is probably Byte-Pair Encoding (BPE). It’s used in models like GPT and combines characters into subword units based on frequency. It is good at compressing vocabulary while keeping important meaning.
Q. Why need a tokenizer?
A. You need a tokenizer because machines don’t understand raw text. Tokenizers split that text into chunks—like words or subwords—that models can process. It’s basically the first step in converting human language into something AI can work with.
Q. What are tokens in NLP?
A. Tokens are the individual pieces of text, like words, subwords, or characters, that NLP models use to understand language. So, the sentence “I’m happy” might be split into \[“I”, “’m”, “happy”] depending on the tokenizer.
Q. What is the difference between a tokenizer and an embedding?
A. A tokenizer splits text into smaller parts (tokens). Embedding takes those tokens and turns them into numbers (vectors) that the model can understand. Tokenizer = chop up the text. Embedding = give each chunk meaning with numbers.
Our Latest Insights



Leave a Comment