Table of Contents
Our Global Presence :
Home / Blog / AI/ML
What is AI-Ready Data and How to Make Your Data AI-Ready
by
May 13, 2025

by
May 13, 2025
AI systems depend on data to discover patterns and make predictions which supports decision-making processes. The value that AI produces depends entirely on the quality of data it processes. According to the MIT Sloan Management Review, 70% of organizations experience no positive results from their AI projects because of inadequate data quality, faulty data strategies and insufficient planning.
The global economic outlook for AI indicates that it will produce $4.4 trillion per year by 2030 which makes high-quality data preparation more vital than ever. Data accuracy, relevance and structural clarity has evolved from being a mere back-end requirement to become a strategic foundation that enables business expansion and creative development.
Generative AI advances have created rapid progress in automated data processing systems. Studies by Accenture indicate that generative AI enables the automation of 95% of data processing duties which minimizes labor-based work while shortening data analysis duration.
Creating AI-ready data requires solid data management and improved quality standards combined with smart integration processes. Organizations that focus on these basic requirements will experience lower failure rates and achieve both responsible AI scalability and tangible return on their investment.
This article provides insight into the meaning of AI-ready data, explains common obstacles and describes concrete methods for matching data with particular AI use cases. These principles enable businesses to achieve tangible value from their Artificial Intelligence investments through proper implementation.
What Does “AI-Ready Data” Mean?
AI-ready data is information that has been carefully cleaned, structured, and optimized for use in artificial intelligence systems. The amount of data matters less than the quality of data which contains accurate values and relevant information properly formatted to match AI model requirements. This ensures efficient analysis, faster processing, and more reliable outcomes.
To be considered AI-ready, data must meet the following key standards:
- Well-Structured: The data must be organized in a way that supports the specific needs of the AI system, promoting smooth integration and processing.
- Rich in Context: It must offer enough contextual information for the AI to generate meaningful, actionable insights tailored to specific objectives.
- High Quality: It should be accurate, complete, and consistent, minimizing errors and reducing the risk of bias in Machine Learning (ML) results.
In short, AI-ready data consists of abundant information that has been specifically refined for fueling intelligent applications and data-driven decisions.
Unsure What ‘AI-Ready Data’ Really Means or How to Get There?
Transform your data into AI-ready assets. We optimize, clean, and structure your data, unlocking its full potential for seamless AI integration and smarter business operations.
Key Traits of AI-Ready Data
1. Structured Format
Although AI systems handle unstructured inputs including text, images and video without issues, the integration of structured data leads to faster and more precise processing capabilities. The formatting of structured data into tables or databases makes it possible for computers to ask queries and analyze information with decreased computational needs. This structured arrangement enables AI models to function at higher speeds while providing quicker insights. For example, artificial intelligence models utilize structured customer data such as purchase history, demographics and engagement metrics to develop customized marketing strategies which enhance customer loyalty and conversion rates.
2. High Quality
An organization becomes truly AI-ready only when its data demonstrates highest levels of accuracy, consistency and reliability. High quality prevents inaccurate insights and incorrect predictions because it decreases the occurrence of errors and redundant information. Strongly validated data free from inconsistencies ensures AI models can operate smoothly without encountering “noisy” or incorrect inputs. This leads to more dependable outputs and supports better strategic decisions.
3. Timeliness and Relevance
Up-to-date data sets that are relevant to context represent the foundation for being ready to implement AI. Poor choices frequently arise from using old or unimportant information especially in fields that change rapidly like financial or health services. AI-ready data operate with continuously updated content that matches the requirements of current operational needs. For instance, Artificial Intelligence (AI)-powered stock trading systems leverage real-time market information through programmable algorithms to modify investment approaches instantly which enhances quick marketplace reactions and reduces financial hazards.
4. Comprehensive Coverage
AI-ready data needs to include a comprehensive collection of important variables that should maintain diversity. AI systems achieve better prediction outcomes thanks to their diverse input capabilities that enable them to simulate complex real-world scenarios. Take customer behavior analysis as an example, an AI model that uses data on past purchases, browsing history, demographic details, and real-time engagement is better positioned to understand buying patterns and predict future behavior. The holistic view enables better recommendations that drive improved marketing strategies toward satisfied customers with increased sales.
5. Data Integrity and Security
The safety of AI systems depends on trusted data that remains safeguarded and unchanged. Ensuring the protection of data from alteration or breach requires the implementation of encryption, access limitations and verification protocols. These safeguards protect the data’s authenticity and meet regulatory standards for privacy protection. In sensitive domains like healthcare, maintaining strong AI data security is crucial for protecting patient confidentiality and preserving trust in AI-powered systems.
Essential Factors Powering AI-Ready Data
Businesses need to understand the fundamental factors that create a demand for AI-ready data to achieve maximum AI technology benefits. By addressing these core factors, businesses can enhance AI data readiness and performance.
1. Blending Structured and Unstructured Data
Generative AI works efficiently with both organized and unorganized data sources including database records, video content and natural language. Organizations need to develop strategies which manage combination and integration of multiple data formats. The success of data integration allows organizations to achieve AI readiness that delivers advanced capabilities and deeper insights into multiple content varieties.
2. Evolving Data Management Practices
As AI continues its explosive expansion, it requires new flexible data management solutions to replace traditional approaches. The optimization of AI-ready data strongly depends on advanced approaches including data fabrics and augmented data management. Through knowledge graphs, AI models achieve better data context alignment, integration and retrieval capabilities which results in enhanced model intelligence. The evolving marketplace demonstrates an increasing requirement for data management solutions which generate efficient AI-based insights, an area increasingly supported by AI development services.
3. Data Quality and Accessibility
AI systems depend on high-quality data for effective performance.Yet many organizations underestimate AI-specific data challenges, including bias and inconsistency. Without solid AI data readiness, even top AI development companies struggle to deliver robust solutions. Creating AI-ready data means ensuring it is accurate, representative, and unbiased. Working to address these obstacles creates a reliable data framework which helps generate trustworthy and dependable AI outcomes.
4. Addressing Bias and Hallucinations
AI-specific problems including bias and false outputs need careful data management protocols. The preparation of data for AI systems depends heavily on effective data governance and quality assurance practices to reduce associated risks. Taking proactive measures regarding these issues produces accurate and trustworthy AI performance that is objective in nature.
5 Steps to Achieving AI-Ready Data
For government bodies seeking to harness artificial intelligence, the journey begins with a mission-aligned data strategy. By narrowing their focus to achievable, high-impact initiatives, agencies can concentrate on fewer, more relevant datasets. This strategic prioritization favors momentum over perfection, speeding up AI data readiness.
As use cases are defined, it’s important to confirm the presence and accessibility of the required data. Familiarity with core data assets grows over time, building institutional knowledge. Well-planned efforts also allow agencies to group similar use cases, which helps conserve time and resources. Ultimately, by anchoring efforts in mission-driven priorities, agencies can build early successes that drive broader buy-in and sustained artificial intelligence technology growth.
Following these five steps ensures that agencies curate the right data to meet AI-readiness standards:
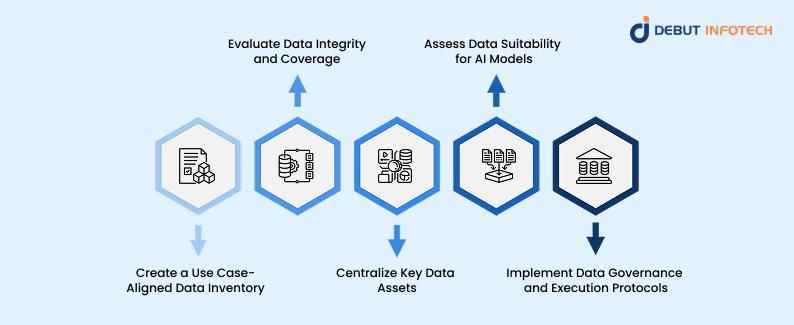
Step 1: Create a Use Case-Aligned Data Inventory
The first move is to identify datasets that align with top-priority AI initiatives. This should be led by roles like the Chief Data Officer or data stewards, in partnership with operations leads. They must determine data ownership, locations, and access methods, taking into account agency-specific platforms and infrastructure.
A perfect example is a transportation agency that just launched an internal audit to surface datasets related to traffic optimization. The result was a searchable data inventory shared across departments, enabling rapid experimentation and prototyping.
Step 2: Evaluate Data Integrity and Coverage
The effectiveness of AI depends heavily on clean, comprehensive data. Agencies should perform thorough evaluations of data sources tied to each use case. For example, a city’s emergency services department conducted a completeness check for response-time datasets, using only 15% of its available data to kick off predictive modeling for resource deployment.
By working with existing data, agencies can build early wins. A regional health department, for instance, used limited but high-quality patient flow data to improve clinic efficiency by nearly 2x, setting the stage for future data-sharing partnerships.
Step 3: Centralize Key Data Assets
Selected datasets should be consolidated into a unified repository, whether in an existing data lake or a newly established cloud platform. This shared environment empowers cross-functional teams to collaborate and innovate more easily.
As an example, a public utilities board integrated consumption data from dozens of billing and monitoring systems into one central cloud solution. This improved accessibility for analysts, customer service teams, and third-party consultants working on sustainability initiatives. This centralized approach lays the groundwork for building a robust AI agent ecosystem.
Step 4: Assess Data Suitability for AI Models
Once centralized, data must be tested for suitability in AI applications. This includes checking volume, cleanliness, relevance, and granularity. Aggregated datasets might suffice for trend forecasting, while case-by-case prediction models may require raw, detailed records.
Key actions include:
- Filtering only the most relevant records.
- Creating reusable data schemas.
- Identifying quality gaps and resolving them.
- Enhancing the dataset with external or third-party data when needed.
For example, a public education department working on dropout prediction realized their student datasets lacked attendance consistency. By cleaning formats and integrating parental engagement data, they created a more accurate model for early intervention.
Step 5: Implement Data Governance and Execution Protocols
Strong data governance frameworks are critical to AI-readiness. These frameworks should cover stewardship roles, quality benchmarks, and access rules, but remain lean enough to promote agility.
For example, a public pension authority safeguarding over 200 sensitive datasets designed a data governance model grounded in industry standards like ISO/IEC 27001. They introduced a tiered-access model and began transitioning to DevSecOps workflows for faster implementation.
In AI development, flexibility is key. Agencies must shift from traditional waterfall approaches to iterative models. Though public institutions may lean toward caution, evolving into agile, governance-minded organizations is essential for sustained AI impact. Leveraging AI tools effectively can help streamline these processes and ensure faster, more efficient data management.
Challenges to AI-Ready Data
The journey to AI-ready data improves when organizations handle multiple challenges that enable AI to reach its complete potential. Without a solid data foundation, even the most advanced AI tools can falter. Here are some challenges faced:
1. Fragmented Data Sources
When teams collect and store data independently such as marketing tracking customer behavior, valuable connections between datasets remain untapped.
Impact: AI algorithms need a holistic dataset to find correlations and derive insights. Fragmentation leads to incomplete inputs, resulting in narrow, misleading outputs.
Solution: Create a unified data architecture like a cloud-based data warehouse that consolidates datasets across departments. Promote data interoperability through APIs and shared standards to ensure seamless information flow. This is one of the key steps when considering how to make data AI-ready and avoiding fragmentation in your datasets.
2. Lack of Standardization
Disparities in data labeling, formats, and terminologies often occur when different systems or regions handle data without coordination.
Impact: For example, one system using “Yes”/”No” while another uses “1”/”0″ can confuse AI training processes. Inconsistent records degrade the model’s learning and predictive power.
Solution: Adopt enterprise-wide data standards and taxonomies. Use automated tools to enforce schema alignment and normalize incoming data, helping AI models interpret information accurately. If you’re facing these challenges, working with AI consulting firms can help implement standardized data structures, ensuring smoother data processing and better AI readiness.
3. Poor Data Hygiene
Erroneous or incomplete data like duplicated customer profiles or unverified sensor readings compromises model training and leads to faulty predictions.
Impact: A predictive maintenance model fed with flawed machine operation logs may misinterpret risks, causing downtime or operational failures.
Solution: To ensure AI-ready data, implement rigorous data cleansing workflows. Use anomaly detection, deduplication algorithms, and enrichment tools to elevate data reliability and readiness for AI use.
4. Data Privacy and Governance Challenges
AI projects process significant amounts of sensitive data which could include health records of users and financial transactions. Without strong governance, this becomes a liability.
Impact: Data misuse or unauthorized access can breach compliance regulations (e.g., GDPR, HIPAA), resulting in fines and loss of user trust.
Solution: Organizations must implement strong security systems with multiple authentication factors and encryption that extends throughout the entire system. The adoption of privacy-protecting AI methods through synthetic data creation and homomorphic encryption safeguards responsible data usage. For businesses looking to integrate AI while safeguarding privacy, AI Copilot development can offer a secure, user-friendly solution.
Why Is AI-Ready Data Essential?
Faster AI Development Cycles
Having AI-ready data significantly reduces the time data teams spend wrangling raw inputs, allowing them to concentrate on training, tuning, and deploying intelligent models. In many industries, data can come in messy formats (think of handwritten medical notes or fragmented sensor data from IoT devices). Data scientists start algorithm refinement processes as soon as data goes through pre-structured tagging and verification procedures. Faster development of AI applications becomes possible through this speed which enables organizations to stay ahead in industries such as healthcare, logistics and fintech.
Lower Costs with Smarter Data Management
Preparing raw data from scratch can drain resources. By starting with AI-ready data, organizations cut down on the manual effort needed for cleaning, labeling, or formatting. For instance, in agriculture tech, using standardized drone imagery datasets saves teams weeks of preprocessing work. This cost-saving benefit compounds when AI solutions are deployed at scale. Teams can focus budgets on innovation rather than preparation, making AI adoption more sustainable and scalable.
Seamless MLOps for Scalable AI
MLOps bridges the gap between model development and real-world deployment. AI-ready data helps ensure that the data used in training closely mirrors what’s encountered in production, be it live user interactions on an e-commerce platform or traffic patterns for smart city infrastructure. This alignment reduces the risk of model drift and enables more efficient model updates, testing, and monitoring. In turn, businesses can keep AI systems running smoothly with minimal downtime and fewer post-deployment fixes.
Boosted Model Performance
AI systems are only as good as the data that fuels them. When data is accurate, complete, and timely, models produce more reliable outputs. For example, a financial institution that trains its fraud detection system on well-prepared transaction data is far more likely to detect anomalies effectively. Clean and context-rich datasets minimize the noise that can throw off predictions, resulting in smarter automation and better decision-making across the board. To ensure long-term success, companies may also need to hire AI developers skilled in refining and optimizing these complex data workflows.
Feeling Overwhelmed by Data Chaos? Let’s Untangle It Together.
Messy data won’t get you far with AI but you don’t have to do it alone. We’ll audit, clean, and structure your datasets into AI-ready assets. No fluff, just clarity and impact.
End Note
The modern data-driven environment requires AI-ready data as the essential foundation to fully harness artificial intelligence capabilities.Data quantity alone is insufficient for organizations as they must also prioritize accuracy, structure and security while maintaining alignment with business objectives. High-quality data enhances model effectiveness, minimizes errors, eliminates bias and allows teams to save time which they can dedicate to innovative tasks. With proper governance and security, organizations can build trust, stay compliant, and scale AI efforts more efficiently. By investing in AI-ready data today, organizations can create a foundation for rapid advancement while ensuring their ability to adapt and sustain future success.
Frequently Asked Questions (FAQs)
Q. What Exactly is AI-Ready Data?
A. In simple terms, AI-ready data refers to well-structured, high-quality information that is readily usable for training machine learning models and powering AI applications, requiring little to no additional engineering work.
Q. Why is AI-ready data important?
A. It enables organizations to build tailored knowledge assets for specific functions and enterprise needs, enhancing the accuracy of AI models while lowering training costs.
Q. What is AI-Generated Data?
A. AI-generated synthetic data is created using sample-based methods. To produce this type of data, a sufficiently large dataset is required for generative AI models to learn from. These models analyze the original data in-depth, capturing its underlying patterns and characteristics to generate new, similar data.
Q. What are AI datasets?
A. In the context of machine learning and artificial intelligence, a dataset is a structured collection of data used to train and evaluate algorithms and models.
Talk With Our Expert
Our Latest Insights




USA
Debut Infotech Global Services LLC
2102 Linden LN, Palatine, IL 60067
+1-703-537-5009
info@debutinfotech.com
UK
Debut Infotech Pvt Ltd
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
Debut Infotech Pvt Ltd
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-703-537-5009
info@debutinfotech.com
INDIA
Debut Infotech Pvt Ltd
C-204, Ground floor, Industrial Area Phase 8B, Mohali, PB 160055
9888402396
info@debutinfotech.com
Copyright © 2025, Debut Infotech. All rights reserved. | Privacy Policy
Leave a Comment